Anlamlı bir p-değeri nasıl pratik olarak önemsiz olabilir?
p < 0.001 bazen gerçek hayatta hiçbir şey ifade etmez. - istatistiksel anlamlılığın neden pratik anlamlılıktan farklı olduğunu bir futbol örneği üzerinden tartışıyoruz.
Football Analytics
Yazar
Murat Seyhan
Yayınlanma Tarihi
21 Mart 2026
Eğer Türkiye’de futbol tartışmalarına aşinaysanız, aslına bakarsanız sadece Türkiye’ye özel değil, genel olarak herhangi bir yerde futbol konuştuysanız genel bir konsensüs olduğunun farkına varmış olabilirsiniz. “Büyük takımlar pres yapar.” Büyük takım topu rakibe verip hata yapmasını beklememeli. Futbol kültürümüzde pres her daim iyi bir şey gibi görülür. Bu sadece Türkiye’ye özgü de değil aslında. Klopp’un Liverpool’u gegenpressing ile Avrupa şampiyonu olduktan sonra, neredeyse her yerde maç sonu yorumlarında aynı şeyleri duyar olduk: “Yüksek pres yaptılar”, “topu tehlikeli bölgelerde geri kazandılar”, “topsuz oyundaki yoğunlukları fark yarattı.” Bu, artık takım iyi oynadığında yorumcuların tekrar ettiği standart cümlelerden biri hâline geldi.
Bunun neden cazip geldiğini anlamak zor değil. Pres, çabalı bir iştir; saldırgan görünür; sanki maçı daha çok isteyen takımın yaptığı şeymiş gibi algılanabilir. Ve ilk bakışta belki de veriler de bunu destekliyor gibi duruyor.
PPDA Nedir ve Futbol Analitiğinde Neden Yer Etti?
Futbol analitiği dünyasında baskı yoğunluğunu ölçmek için kullanılan, ilk olarak Colin Trainor tarafından geliştirilmiş çok temiz bir metrik var: PPDA, Passes Per Defensive Action. Colin futbol analitiği topluluğuna önceden sadece hissiyat ve sezgiyle gözlemlenebilen bir olguyu sayısallaştırabilmemiz için basit ama çok güçlü bir araç kazandırdığı için bence hatırlanmayı hak ediyor. Fikir de aynı şekilde çok sezgisel. Karşı takımın, siz bu konuda (engellemek üzere) bir şey yapana kadar kaç pası başarıyla tamamladığını sayıyorsunuz.
Bir müdahale, araya girme, faul gibi. Düşük PPDA karşı takımı hızlıca, henüz pas yapamadan bozuyorsunuz demek oluyor. Yüksek PPDA ise yerleşmeye çalışıp, topla aksiyona girmeden onların topu döndürmesine izin verdiğiniz anlamına geliyor. Sayı ne kadar küçükse, onları o kadar sıkıyorsunuz.
Esasen incelikli düşünülmüş bir metrik, ve takımların nasıl savunma yaptığı ile alakalı gerçek bir şeyi yakalıyor. Ancak benim vurgulamak istediğim sorun PPDA’nın kendisi dğil aslında. Asıl isteğim, bunun gibi bir metriği alıp, istatistiksel testlerle sınayıp, alabildiğine küçük ama parlak bir p-value bulup, erkenden kafa yormayı bırakmak üzerine konuşmak.
Presin gerçekten sonuca dönüşüp dönüşmediğini test etmek için, 2015/16 sezonundan itibaren beş büyük Avrupa ligindeki tüm maçlara ait StatsBomb olay verisini kullandım: Premier League, La Liga, Serie A, Bundesliga ve Ligue 1. Bu da toplam 1.823 maç, yani 3.646 takım-maç gözlemi demek. Her biri için, ham olay düzeyindeki veriden PPDA’yı hesapladım (duran top paslarını hariç tutarak) ve maç sonucunu puan cinsinden kaydettim: galibiyete 3, beraberliğe 1, mağlubiyete 0.
Soru oldukça basit: “Daha sert pres yapmak daha fazla puan getiriyor mu?”
NotVeri ve PPDA Hesabıyla İlgili Notlar
PPDA, StatsBomb’un olay düzeyindeki verisinden şu şekilde hesaplanır: (rakibin hücum bölgesinde açık oyunda yaptığı paslar) / (savunma bölgesindeki top kapmalar + araya girmeler + fauller). Pay kısmına duran top pasları dahil edilmez; yani kale vuruşları, taç atışları, serbest vuruşlar, kornerler ve santra pasları hesaplamanın dışında bırakılır. StatsBomb bu aksiyonları type=="Pass" olarak kaydeder ve ayrıca bir pass_type alanı içerir; ancak Opta’nın PPDA’ya ilişkin orijinal formülasyonu bu pas türlerini ayrı değerlendirir. Bu dışlama yapıldığında lig ortalamaları da yayımlanmış referans aralıklarla uyumlu hâle gelir (yaklaşık 10–13 bandı).
Saha bölgelerine ilişkin eşikler de yerleşik algıyı takip eder: savunma yapan takımın aksiyonları için loc_x > 48 (kendi yarı sahası), rakibin pasları için ise loc_x < 72 kullanılır. Her maç veri setinde iki satır üretir — her takım için bir satır.
Matches: 1,823
Team-match observations: 3,646
Leagues: 1. Bundesliga, La Liga, Ligue 1, Premier League, Serie A
p-Değeri’nin Size Söyleyecekleri Var
Yapacağımız kurulum şu şekilde:
Boş hipotez (H₀): Agresif pres yapan takımlarla (PPDA 10’un altında olanlar) geride bekleyen takımların (PPDA 15’in üstünde olanlar) maç başına topladıkları puan arasında fark yoktur.
Alternatif hipotez (H₁): Agresif pres yapan takımlar daha fazla puan toplar.
Gruplar şöyle: agresif pres kategorisinde 1.496 gözlem, pasif savunma kategorisinde ise 905 gözlem var. Şimdi iki örneklemli Welch t-testi uygulayalım.
# Agresif pres yapan takımların (PPDA < 10) puanlarını almak için veri çerçevesini filtreleagg = df[df['ppda'] <10]['points']# Pasif savunma yapan takımların (PPDA > 15) puanlarını almak için veri çerçevesini filtrelepas = df[df['ppda'] >15]['points']# İki grubun ortalamalarını karşılaştırmak için Welch t-testini uygula (varyansların eşit olmadığı varsayılır)t_stat, p_val = stats.ttest_ind(agg, pas, equal_var=False)# Özet istatistikleri ve test sonuçlarını yazdırprint(f'Agresif pres (PPDA < 10): n = {len(agg)}, ortalama = {agg.mean():.3f} puan/maç')print(f'Pasif savunma (PPDA > 15): n = {len(pas)}, ortalama = {pas.mean():.3f} puan/maç')print(f'\nWelch t = {t_stat:.2f}, p = {p_val:.6f}')
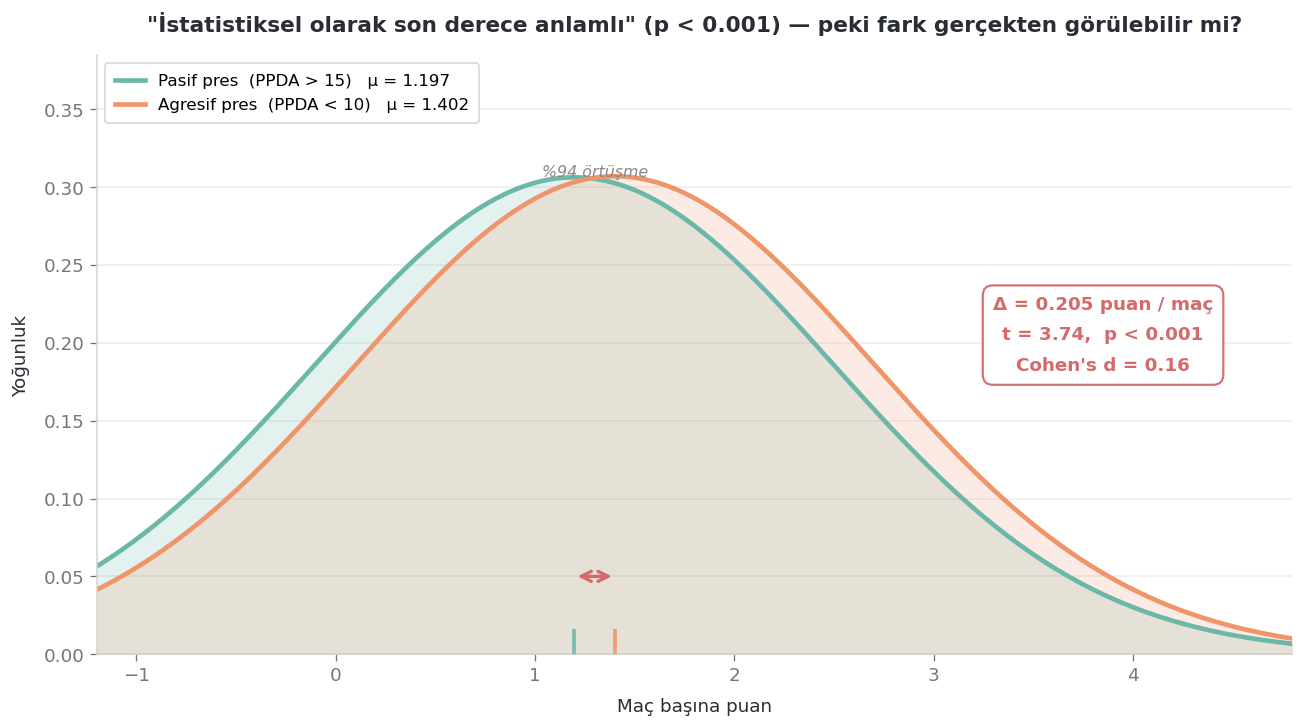
Agresif pres (PPDA < 10): n = 1496, ortalama = 1.402 puan/maç
Pasif savunma (PPDA > 15): n = 905, ortalama = 1.197 puan/maç
Welch t = 3.74, p = 0.000188
İstatistiksel olarak son derece anlamlı. Bu şu demek; eğer presin gerçekten maç sonuçları üzerinde hiçbir etkisi olmasaydı, yalnızca tesadüfen bu kadar büyük bir farkı görme olasılığınız %0,02’nin altında olurdu. Bu durumda boş hipotez pek de inandırıcı görünmüyor. Ve bence insanların sezgisel tepkisinin devreye girdiği yer tam da burası: İçgüdülerimiz hemen “Biliyordum, pres işe yarıyor.” diyor.
Bu çok doğal bir tepki. Zihnimiz bir nedensellik makinesi gibi çalışıyor; zaten inandığımız bir şeyi test de doğruladığında, onu çok hızlı kabul ediyoruz. p < 0.001 mi? Tamamdır. Devam.
Açıkçası, gerçek hayattaki birçok durumda süreç gerçekten tam da böyle işliyor. Kurumsal firmaların analitik departmanlarında, hızlı karar verilmesi gereken durumlarda, bir şeyin önemli olup olmadığına dair çabuk bir okuma yapmanız gereken senaryolarda, p-value istatistiksel düşüncenin adeta fast food’u hâline gelmiş durumda. Sipariş veriyorsunuz, cevabı saniyeler içinde alıyorsunuz, sonra sıradaki konuya geçiyorsunuz. Kararı verecek kişi “anlamlı” sonucunu görüyor ve harekete geçiyor. Etkinin gerçekte ne kadar büyük olduğunu kontrol etmek için kimse durmuyor. Bunun sebebi insanların tembel olması değil; iş akışı her zaman buna alan tanımıyor ve “anlamlı” kelimesi sanki soruyu zaten cevaplamış gibi hissettiriyor.
Ama aslında cevaplamış olmuyor. p-value bize yalnızca şu sonucu verir: Eğer ortada gerçekten hiçbir etki olmasaydı, (burası çok önemli) bu bulgu şaşırtıcı olurdu. Etkinin ne kadar büyük olduğuna dair ise kelimenin tam anlamıyla hiçbir şey söylemedi. Oysa asıl, önem vermek gerekip gerekmediğini belirleyen şey, tam olarak o etkinin büyüklüğüdür.
p-Value Neleri Gizliyor
Verimizin arkasındaki bazı istatistiksel gerçekleri raporlayalım.
ham etkinin bağlam içindeki karşılığı
agresif pres yapan takımlarla (PPDA < 10) pasif kalan takımların (PPDA > 15) maç başına puan farkı
bu, iki grubun ortalamaları arasındaki farktır; yani sahada pratikte hissedeceğiniz puan farkı
pooled standart sapma
iki grubun yayılımını tek bir ölçekte birleştirir (etki büyüklüğünü normalize etmek için)
Cohen’s d için daha istikrarlı bir payda sağlar
Cohen’s d etki büyüklüğü
ortalama farkının birleştirilmiş standart sapmaya bölünmesiyle elde edilir
birimsizdir; bu yüzden çalışmalar arasında karşılaştırılabilir
sektörlerin genelinde yaygın kullanım: 0.2 küçük, 0.5 orta, 0.8 büyük etki
üstünlük olasılığı (P(superiority))
rastgele seçilen agresif pres yapan bir takım sonucunun, rastgele seçilen pasif bir takım sonucunu geçme olasılığı
normallik varsayımı altında Cohen’s d’den türetilir
%50 yazı tura gibi; %50’nin üstü, agresif tarafın genellikle küçük de olsa üstün geldiğini gösterir
dağılım örtüşmesi
normalize edilmiş iki sonuç eğrisinin yüzde kaç oranında örtüştüğünü gösterir
%100’e ne kadar yakınsa, p çok küçük olsa bile pratikte neredeyse hiç ayrışma yok demektir
Bunlar, istatistiksel olarak anlamlı bir p-value’nun pratikte de gerçekten anlamlı olup olmadığı konusunda fikir verebilecek olan daha iyi “büyüklük” göstergeleridir.
İki grup arasındaki gerçek ortalama fark ne? Maç başına yalnızca 0.205 puan.
Cohen’s d değeri ise 0.16 çıkıyor — bu da genellikle “küçük” etki olarak adlandırılan eşiğin bile altında. Pek çok kişi bunu ihmal edilebilir düzeyde değerlendirir.
Şimdi bunun pratikte ne anlama geldiğini gerçekten hissetmenizi istiyorum. Her iki gruptan rastgele birer maç seçip “hangisi daha fazla puan üretti?” diye sorsaydınız, agresif pres yapılan maç zamanın %54’ünde önde çıkardı. Yani bu, yazı tura olasılığının yalnızca 4 yüzde puan üstü demek. İki dağılımın örtüşme oranı ise %94.
Bu şu demek oluyor: Birisi her iki gruba ait sonuçları etiketlerini kaldırıp birbirine karıştırsa, bunları tekrar doğru şekilde ayırmanız neredeyse mümkün olmazdı.
p-value bize “anlamlı” diyor. Ama etki büyüklüğü bambaşka bir hikâye anlatıyor: Evet, ortada bir etki var, ama çıplak gözle bakınca bunu fark etmekte epey zorlanırsınız.
p-Değeri Neden Bu Kadar Küçüktü?
Bir p-value iki şeyin fonksiyonudur: etki büyüklüğü ve örneklem büyüklüğü. t-istatistiği de şöyle yazılır:
t = (ortalama farkı) / (standart hata)
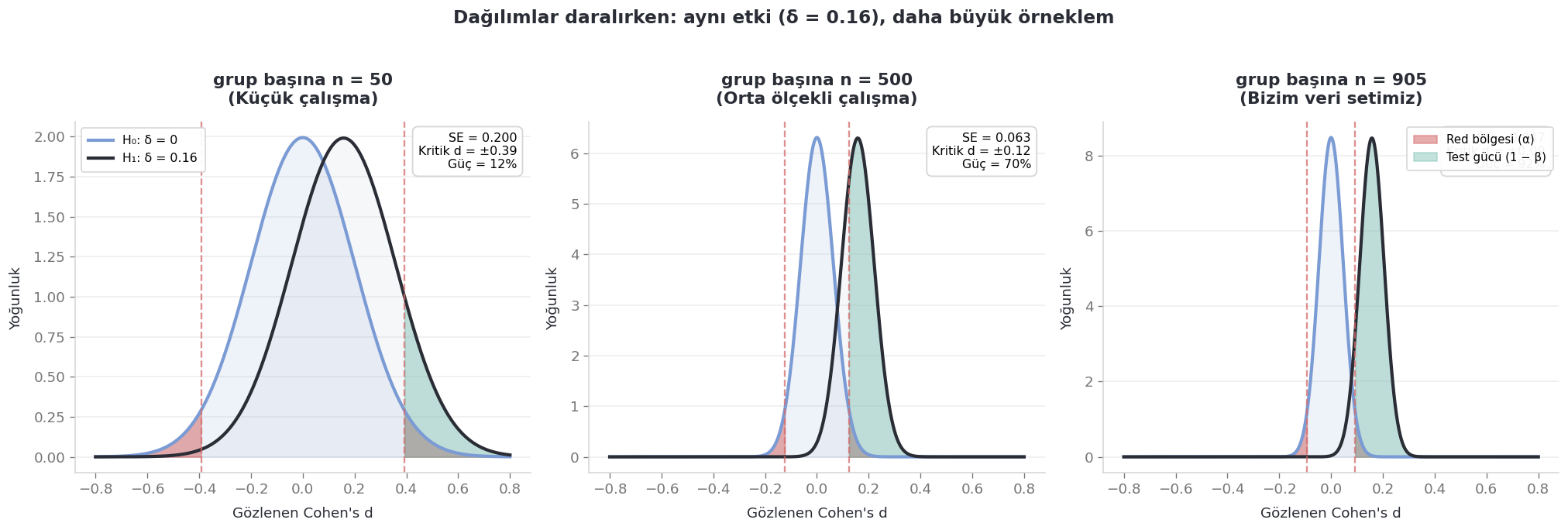
Örneklem büyüdükçe standart hata küçülür. Grup başına yaklaşık 2.400 gözlem olduğunda, aradaki fark tırnak kadar bile olsa büyük bir t-istatistiği üretebilir. Bunun ardındaki matematik, farkın gerçekten “anlamlı” olup olmadığıyla ilgilenmez; yalnızca tespit edilebilir olup olmadığıyla ilgilenir.
Yukarıdaki iki eğriyi düşünün. Biri sıfır hipotezi altındaki dağılımı (hiç etki yok), diğeri ise alternatif hipotez altındaki dağılımı (küçük de olsa bir etki var). Örneklem küçük olduğunda her iki eğri de geniş olur ve neredeyse tamamen üst üste biner. Test bunları birbirinden ayıramaz. Ama n büyüdükçe iki eğri de daralır, tepeleri keskinleşir ve sonunda en ufak fark bile istatistiksel anlamlılık eşiğini aşar.
Aynı etki — yani tam olarak aynı 0.205 puanlık fark — farklı örneklem büyüklüklerinde test edildiğinde sonuç şöyle görünür:
print(f'{"n (grup başına)":>14s}{"p-değeri":>10s} Anlamlı mı?')print(f'{"-"*14}{"-"*10}{"-"*12}')for n in [50, 200, 500, 1000, 2400]: se = pooled_sd * np.sqrt(2/n) t = mean_diff / se p =2* (1- stats.t.cdf(abs(t), df=2*n-2)) p_str =f'{p:.3f}'if p >=0.001else'< 0.001' sig ='★ Evet'if p <0.05else' Hayır'print(f'{n:>14,d}{p_str:>10s}{sig}')
Bu tabloyu inceleyelim. Etki büyüklüğünü değiştirmedik. Aynı önemsiz fark her satırda aynen duruyor. n = 50 iken p-value “hayır, anlamlı değil” diyor. n = 2.400 olduğunda ise aynı farka “son derece anlamlı” demeye başlıyor. Yani p-value aslında önemli bir şey keşfetmedi — sadece küçük küçük farklılıkları tespit edebilecek kadar veri biriktirdi.
Bu, p-value’nun kusuru değil. Tam tersine, tam olarak tasarlandığı şeyi yapıyor. Sorun, “şaşırtıcı” olanın “önemli” diye yorumlandığı anda başlıyor. Testimiz, ihmal edilebilir düzeydeki bir etkiyi saptayabilecek güce ulaştı. Ama bir şeyi tespit edebilmek, onun gerçekten önem taşıdığı anlamına gelmiyor.
Büyüklüğü Gerçekten Önemliymiş…
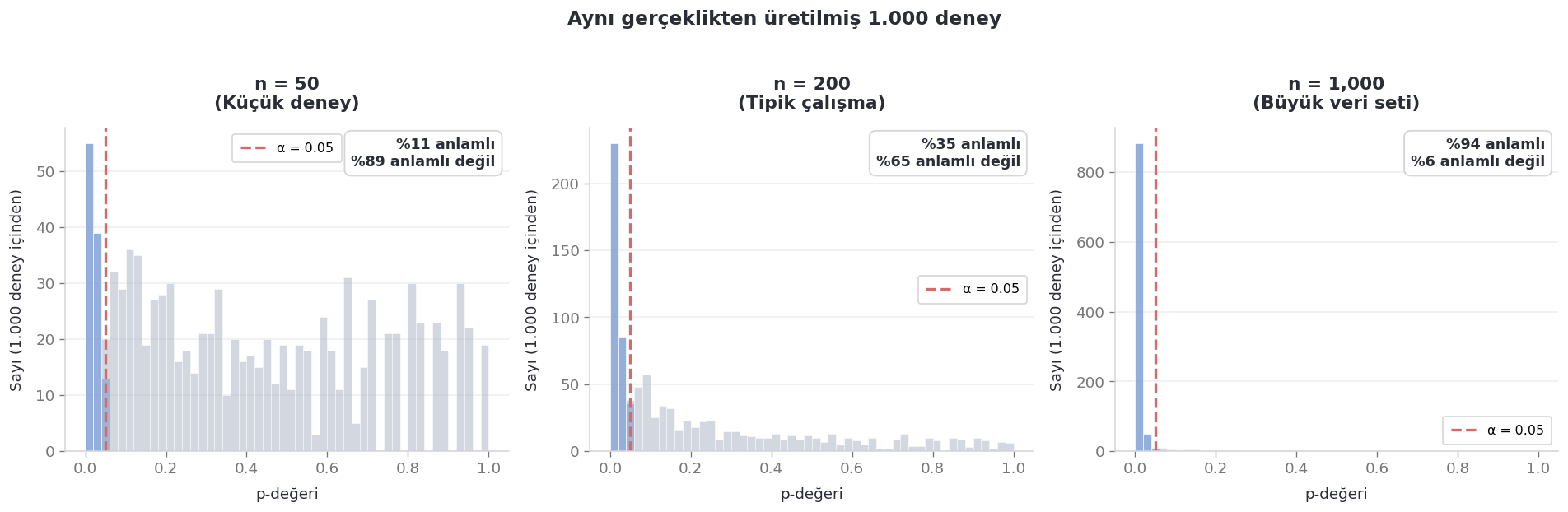
Şimdi veri setinden üç farklı örneklem büyüklüğünde, 1.000 kez yeniden sampling yapalım — her seferinde rastgele alt kümeler çekip yeni bir t-testi uygulayacağız. Altta yatan gerçeklik aynı, gerçek etki aynı.
Grup başına n = 50 olduğunda deneylerin yalnızca %11’i anlamlılık eşiğini geçti. n = 200 olduğunda bu oran %36 oldu. n = 1.000 seviyesinde ise bir anda %93’e sıçradı.
Bunun hakkında biraz durup düşünelim. n = 200 ile aynı soruyu inceleyen iki araştırmacı, “anlamlılık” konusunda aynı sonuca varmaktan daha sık biçimde birbirleriyle çelişirdi. Aynı gerçek, aynı test, ama örnekleme hangi gözlemlerin düştüğüne bağlı olarak tamamen farklı sonuçlar.
Önceki yazıda buna değinmiştim. Tek bir p-value, tek başına karar vermek için güvenilir bir temel değildir. O yalnızca gürültülü bir dağılımdan çekilmiş tek bir örnektir.
Pres Yapmak Takımınıza Gerçekte Ne Kazandırır?
Şimdiye kadar şunu ortaya koyduk: Etki var, ama küçük. Bundan sonra her karar vericinin aslında sorması gereken soru şu: buna göre hareket edersek pratikte ne kazanırız?
Daha önce size gösterdiğim karşılaştırma — agresif pres yapanlarla pasif kalanlar — yanıltıcı, çünkü temelde farklı takımları karşılaştırıyor. Barcelona’nın PPDA’sı düşük ve puan toplamı yüksek olabilir; ama bu, puanların sebebinin pres olduğu anlamına gelmez. İyi takımlar pres yapar, çünkü daha iyi oyunculara sahiptirler, daha fazla topa sahip olurlar, topu rakip yarı sahada geri kazanma ihtimalleri daha yüksektir. Soru, Barcelona’nın küme düşme hattındaki bir takımdan daha fazla puan alıp almadığı değil. Asıl soru şu: eğer sizin takımınız — sizin spesifik takımınız — normalden daha sert pres yapsaydı, daha fazla puan alır mıydı?
Bunun için takım içi analiz yapalım. Her takım için, her maçta PPDA’nın kendi sezon ortalamasından ne kadar saptığını ve bu sapmanın daha fazla mı yoksa daha az mı puan getirdiğini hesaplayalım.
df['ppda_dm'] = df['ppda'] - df.groupby(['competition','team'])['ppda'].transform('mean')df['pts_dm'] = df['points'] - df.groupby(['competition','team'])['points'].transform('mean')slope, _, r_w, p_w, _ = stats.linregress(df['ppda_dm'], df['pts_dm'])print(f'Within-team correlation: r = {r_w:.4f}, R² = {r_w**2:.4f}, p = {p_w:.4f}')print(f'Slope: {slope:.5f} points per 1-unit PPDA change')print(f'\nWhat does a tactical shift actually buy you?')print(f' Lower PPDA by 2 → {slope *-2*38:+.2f} extra points/season')print(f' Lower PPDA by 5 → {slope *-5*38:+.2f} extra points/season')
Within-team correlation: r = -0.0429, R² = 0.0018, p = 0.0096
Slope: -0.00855 points per 1-unit PPDA change
What does a tactical shift actually buy you?
Lower PPDA by 2 → +0.65 extra points/season
Lower PPDA by 5 → +1.63 extra points/season
Cevap neredeyse hiçbir şey. Takım içi korelasyon r = −0.04, R² = %0.2.
Bunu somut bir şeye çevirelim. Diyelim ki bir takım gerçekten anlamlı bir taktik değişime gidiyor ve PPDA’sını 2 puan düşürüyor — bu yaklaşık standart sapmanın üçte biri kadar; yani çok da küçük bir iş değil. Beklenen karşılığı ise tüm sezon boyunca sadece 0.65 ekstra puan. Maç başına değil maalesef, sezon başına. Otuz sekiz maç boyunca daha yüksek fiziksel yük, artan sakatlık riski, daha derin kadro ihtiyacı — ve karşılığında puanın üçte ikisi kadar bir kazanç bekliyoruz.
Hatta Klopp seviyesinde bir dönüşüm düşünün — PPDA’yı 5 puan düşürmek, yani pasif bir orta sıra takımından Avrupa’nın en agresif pres takımlarından birine dönüşmek. Bunun bile getirisi sezon başına yalnızca 1.6 ekstra puan. 10. sıra ile 15. sıra arasındaki farkın on iki puanı bulabildiği bir ligde bu, yuvarlama hatası gibi kalıyor.
team = df.groupby(['competition','team']).agg( ppda_mean=('ppda','mean'), total_pts=('points','sum'), n=('points','count')).reset_index()team['pts_per_match'] = team['total_pts'] / team['n']mid = team[(team['pts_per_match'] >=1.1) & (team['pts_per_match'] <=1.5)]r_mid, p_mid = stats.pearsonr(mid['ppda_mean'], mid['pts_per_match'])print(f'Mid-table teams (1.1–1.5 pts/match): {len(mid)} teams')print(f'Pressing vs points: r = {r_mid:.2f}, p = {p_mid:.2f}')
Mid-table teams (1.1–1.5 pts/match): 44 teams
Pressing vs points: r = 0.04, p = 0.80
Ve özellikle orta sıra takımları arasında — veri setinde maç başına 1.1 ile 1.5 puan arasında ortalama tutturmuş 44 takımda — pres yoğunluğu ile puan arasındaki korelasyon r = 0.04, p = 0.80 çıkıyor. Hem istatistiksel hem de pratik açıdan neredeyse sıfır.
Şimdi burada dikkatli davranmak boynumun borcu, çünkü söylediğim şey presin işe yaramadığı ya da gereksiz olduğu değil. Böyle bir iddia zaten tuhaf olurdu; ayrıca verinin söylediği şey de bu değil. Pres, son derece geçerli bir taktik felsefe. Doğru oyuncu profilleriyle, uygun fiziksel hazırlıkla ve oyuncuların gerçekten içselleştirdiği tutarlı bir oyun modeliyle uygulandığında elbette çok etkili olabilir. Verinin bize söylediği şey daha spesifik: Sadece daha sert pres yapmak, bunu izole bir değişken gibi ele almak ve presi kimin yaptığıyla ya da o presin içinde işlediği sistemin nasıl kurulduğunu hesaba katmamak, kendi başına daha iyi sonuçları güvenilir biçimde öngörmüyor. Ham yoğunluk sayısı tek başına resmin tamamını vermiyor. Oyuncu profiliyle oyun felsefesi arasındaki uyum, en az felsefenin kendisi kadar önemli.
Maliyet-Fayda Meselesi
Bence en çok gözden kaçan kısım tam da burası. Bir bulgunun “ilginç” olmaktan çıkıp gerçekten “eyleme dönüştürülebilir” hâle gelmesi için bir maliyet-fayda analizi gerekir — ve dünyadaki hiçbir p-value bunu size veremez.
Fayda tarafında elimizde, dönüşümün ne kadar radikal olduğuna bağlı olarak, sezon başına 0.65 ile 1.6 ekstra puan var. Maliyet tarafında ise şunlar duruyor: baştan sona bir taktik yeniden yapılanma, farklı transfer profillerine yönelme, daha yüksek kondisyon yükü, daha fazla rotasyon ihtiyacı, daha yüksek sakatlık riski, sezon boyunca oyuncu varlıklarının daha hızlı yıpranması. Bunlar küçük maliyetler değil.
Her müdahalenin bir maliyeti vardır. p-value size yalnızca fayda tarafını gösterir — onu da etkinin büyüklüğünü silip süpüren ikili bir evet/hayır formatında. Size sadece gözlemin “şaşırtıcı” olduğunu söyler. Ama bu faydanın, vazgeçmek zorunda kalacağınız şeyleri gerçekten karşılayıp karşılamadığını asla söylemez.
Bir de şunu düşünün: Aynı çaba duran top organizasyonlarına, savunmadan hücuma geçiş hızına ya da açık oyunda üretilen pozisyonların beklenen gol kalitesine yönlendirilse, pratik etkisi çok daha büyük bulgular elde edilebilir. Bir teknik heyetin pres modelini biraz daha rafine etmek için harcadığı her saat, belki de gerçekten fark yaratacak başka bir konuya harcanmamış bir saattir. Fırsat maliyeti, p-value içinde görünmez; ama bütün maliyetler arasında belki de en önemlisi odur.
“Şaşırtıcı” Demek “Önemli” Demek Değil
Karışıklığın kökeninde bizzat kelimenin kullanımı yatıyor. Günlük dilde “anlamlı” ya da “significant” dediğimizde kastettiğimiz şey önemlidir, sonuç doğurur, harekete geçmeye değerdir. İstatistikte ise bu kelime yalnızca verinin, sıfır hipotezi doğruysa şaşırtıcı göründüğü anlamına gelir. Bunlar aynı kelimeyle ifade edilen ama tamamen farklı iki iddia. Ve zihnimiz bu ikisini birbirinden ayırmakta gerçekten zorlanır çünkü aslında nedensel hikayeler yaratmaya programlıdır.
Bizim sonucumuzu daha dürüst bir şekilde okumak gerekirse, şöyle bir cümle kurmak gerekir: “Pres ile maç sonuçları arasında istatistiksel olarak şaşırtıcı bir ilişki gözlemledik (p < 0.001). Ancak etkinin büyüklüğü ihmal edilebilir düzeydedir (d = 0.16), sonuçlardaki varyansın %1’inden azını açıklamaktadır ve takım içi analiz, pres yoğunluğunu artırmanın sezon başına yaklaşık 0.65 ekstra puan beklentisine işaret eder — bu da muhtemelen beraberindeki maliyetleri karşılamayacak bir kazanım düzeyidir.”
Bu, kimsenin manşetlerde yer vereceği türden bir cümle değil. Ama verinin gerçekten söylediği şey tam olarak bu.
Peki Bu Kadar Bilgiyle Ne Yapacağız?
Bence burada futbolda presten çok daha öteye giden daha genel bir ders var ve bunu olabildiğince net ifade etmek istiyorum — çünkü farklı bağlamlarda dönüp dolaşıp aynı şeye çarpıyorum.
Bir futbol kulübü, biraz daha derin düşününce, aslında bir üründür. Performans metrikleri vardır, kaynakları sınırlıdır ve her taktik ya da transfer kararı, bu kaynakların en iyi getiriyi sağlayacak şekilde nereye tahsis edileceğine dair bir ifade niteliği taşır. Üstelik bu sadece futbola özgü de değil. Herhangi bir ürün yönetiyorsanız, bir iş yürütüyorsanız ya da hangi alanda olursa olsun veriye dayalı kararlar alıyorsanız, aynı mantık geçerlidir. Ürününüzün performansını ölçebilirsiniz, testler yapabilirsiniz, p-value’lar elde edebilirsiniz. Ama “anlamlı” sonucunda durup etkinin ne kadar büyük olduğunu, hangi maliyetle geldiğini ve başka alternatiflere kıyasla ne ifade ettiğini sormazsanız, eksik bilgiyle karar veriyorsunuz demektir.
Bu yüzden bence olması gereken şu: İstatistiksel olarak anlamlı bir sonuç gördüğünüz her seferde — ister pres yoğunluğu, ister dönüşüm oranları, ister yeni bir özelliği canlıya almak olsun — kendinize üç soru sorun:
Birincisi: Gözlemlenmiş etki büyüklüğü ne? Sadece “sıfırdan farklı mı?” değil; sizin için gerçekten anlam taşıyan birimlerle ne kadar büyük?
İkincisi: Buna göre hareket etmenin maliyeti ne? Sadece para değil; odak, zaman, fırsat maliyeti… Bunun peşinden giderken neyi yapmıyor olacaksınız?
Üçüncüsü: Sonucu zaten etkilediğini bildiğimiz temel etkenleri kontrol ettiğinizde ne oluyor? Etki hâlâ ayakta kalıyor mu, yoksa gürültü içinde eriyip gidiyor mu?
“İstatistiksel olarak anlamlı” demek, “istatistiksel olarak şaşırtıcı” demektir. Ve kabul edeyim, şaşırtıcı olan ilginçtir. Ama sadece ilginç olması, tek başına stratejinizi değiştirmek için iyi bir gerekçe değildir maalesef.
Veri: StatsBomb açık veri seti, 2015/16 sezonundan itibaren beş büyük Avrupa ligi (1.823 maç). PPDA, duran top pasları hariç tutularak olay düzeyindeki veriden hesaplandı.