Veri analitiğinde, hızlı production kararı verilmesi kültürleşmiş yerlerde sprint review’lar benzer ritüellere sahne olabiliyor: ekrana bir A/B test sonucu yansır, p-value okunur ve bir karar çıkar. p küçükse feature ship, büyükse kill edilir. Data scientist “anlamlı bir fark bulamadık” der, PM bunu “demek ki işe yaramıyor” diye okur. Ama bu iki cümle aynı şeyi söylemiyor. Birincisi verinin yetersiz kaldığı anlamına da gelebilir, ikincisi kesin bir yargı. Aradaki boşluk çoğu zaman kapanmadan karar çıkıyor. “Veri konuştu, devam edelim.” Bu akış o kadar doğal hissettiriyor ki “veri gerçekten konuştu mu, yoksa sadece omuz mu silkti?” sorusu çoğu zaman gündeme gelmiyor.
p-value’nun ne söylediğini ve ne söylemediğini ayrıştırmak, günlük iş akışına kolaylıkla sığan bir düşünce değil. Dashboard’daki sayının yeşil ya da kırmızı olmasına bağlı, karar ya ship ya kill edilebilir. Ama önceki yazımda da farklı bir açısıyla incelediğimiz üzere, p = 0.18 gördüğünde “fark yok” demiş olmuyoruz. Bunun yerine, “bu örneklemle, bu sürede, bu metrikle bir fark gösteremedim” demiş oluyorsun. Bu ikisi arasındaki mesafe, bazen bir feature’ın kaderi kadar geniş olabilir.
Ve tam tersi de mümkün. p = 0.002 gördüğünde “büyük bir fark bulduk” demiş olmuyoruz, “bir fark bulduk ve eğer gerçekte bir fark yoksa, şans eseri farklı bir gözlem elde etmiş olma olasılığımız düşük” demiş oluyoruz. Farkın büyük mü küçük mü olduğu, o sayının içinde yazmıyor. 90.000 kullanıcıyla test çalıştırdığında yüzde yarım puanlık bir kıpırdanma bile “istatistiksel olarak anlamlı” çıkabiliyor.
Bu yazıda, uzun süredir gelişmelerini takip ettiğim oyun sektörü üzerinden ilerlemek istiyorum. Kullanacağımız veri, Cookie Cats adındaki mobil bulmaca oyunundan geliyor.
NotCookie Cats
: Cookie Cats — Tactile Entertainment tarafından geliştirilen match-3 bulmaca oyunu.

Kapı, Bekleme ve Tasarım Tercihi
Bir zamanlar epey meşhurdu, bunu 90.000’den fazla oyuncuyla yapılmış, açık bir A/B testi veri setine konu olmasından da tahmin edebilirsiniz. Test edilen şey basit bir tasarım kararı: oyun ilerledikçe oyuncuların önüne bir “kapı” çıkıyor; bu kapı oyuna devam edebilmek için ya belli bir süre beklemeyi ya da uygulama içi satın alma yapmayı gerektiriyor.
Bu tür kapılar ilk bakışta oyuncuyu engelliyor gibi görünse de, bilinçli bir tasarım tercihi. Hedonic adaptation denen psikolojik fenomene hitap ediyor: oyuncuya zorla bir mola verdirerek oyundan aldığı zevkin zamanla aşınmasını yavaşlatıyor. Aynı zamanda devam etme ısrarlılığını monetize ediyorsunuz — oyuncu, içinde bulunduğu oyuna “sizin için” doğru yerde ara vermek durumunda kalırsa mahrumiyetten dolayı daha çok bağlanıyor; uygulama içi satın alma yapan oyuncu ise zaten oyuna para yatırdığı için daha güçlü bir tutunma eğilimi gösteriyor.
Soru şu: bu kapı 30. seviyeye mi konmalı, 40. seviyeye mi? Basit bir soru, basit bir test ve gerçek kullanıcılar var veri setimizde.
Oyuna ilk defa başlayan her oyuncu rastgele iki gruptan birine atanmış: gate_30 grubuna düşenler 30. seviyede kapıya çarpmış, gate_40 grubuna düşenler 40. seviyede.
Bu rastgele örneklenen bir kontrollü deney gibi kurgulanmış — burası önemli. Rastgele atama, iki grup arasında kapının pozisyonu dışında sistematik bir fark olmamasını sağlamaya yönelik. Benzer oyuncular, aynı dönem, aynı oyun (ekonomist deyimiyle: ceteris paribus) — tek değişen kapının yeri. Veri setinde 90.189 oyuncu var ve gruplar neredeyse eşit büyüklükte: gate_30’da 44.700, gate_40’da 45.489 kişi.
Ölçtüğümüz şey retention — oyuncunun oyuna geri dönüp dönmediği. Veri setinde iki retention metriği var: oyuncunun oyunu kurduktan 1 gün sonra geri gelip gelmediği ve 7 gün sonra geri gelip gelmediği. İkisi de evet/hayır cinsinden. Mobil oyunlarda retention kritik bir metrik: çoğunlukla iş modeli oyuncunun orada kalmasına dayanıyor, reklam geliri ve uygulama içi satın alma gibi monetization yapıları da oyuncunun istikrarlı bir şekilde geri dönme eğilimiyle başlıyor. 7 gün sonra hâlâ oynayan bir oyuncu “tutunmuş” sayılabilir — uzun vadeli değeri muhtemelen yüksektir.
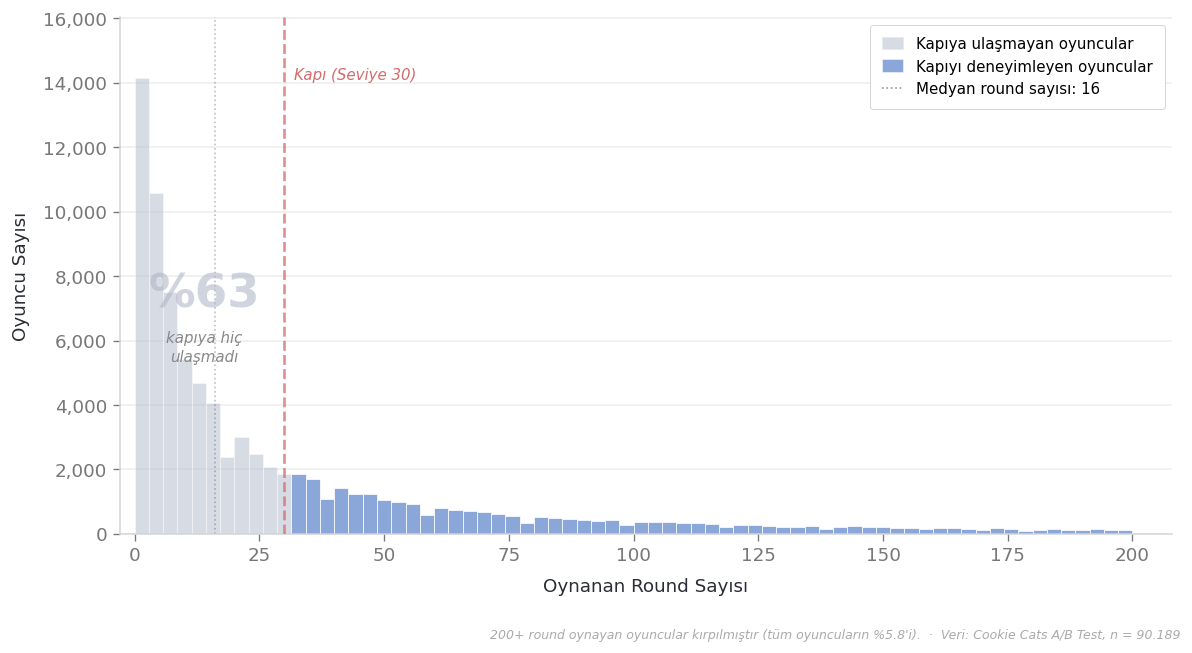
Ek olarak oyuncunun ilk 14 günde kaç round oynadığını gösteren sum_gamerounds var. Bunu engagement düzeyi olarak düşünebiliriz, ama dağılımı çarpık — medyan 16 round, yani oyuncuların yarısından fazlası 16’nın altında kalmış. Oyuncuların yalnızca üçte biri kapının bulunduğu 30. seviyeye ulaşabilmiş. Bu detay önemli ve birazdan geri döneceğiz buraya.
Bu grafiğe bakınca akla doğal bir soru geliyor: oyuncuların üçte ikisi kapıya hiç ulaşmamışsa, onları analize dahil etmenin anlamı ne?
NotNeden Kapıya Ulaşmayanlar da Dahil?
Kapıyı görmeyen biri için gate_30 ile gate_40 arasında bir fark olmasını beklemiyoruz zaten. Bu oyuncuları çıkarıp sadece kapıyı deneyimleyenlere odaklansak daha temiz bir karşılaştırma elde etmez miyiz?
Mantıklı geliyor ama bir tuzağı var. Bir oyuncunun kaç round oynadığı, hangi gruba atandığından bağımsız değil. Gate_30’a düşen bir oyuncu 30. seviyede duvara çarpıp bırakabilir. Aynı oyuncu gate_40’a atansaydı, önünde henüz duvar olmadığı için belki 35. seviyeye kadar devam edecekti. Yani kaç round oynadığın kısmen tedavinin kendisinden etkileniyor. “30 round üstünü filtrele” dediğimizde, aslında kapı pozisyonunun oyuncunun oynama süresini nasıl şekillendirdiğini (yani etkinin bir kısmını) kesip atmış oluyoruz. Daha da önemlisi, gate_30’da kapıya rağmen devam etmeyi seçmiş bir oyuncuyla gate_40’da henüz kapıyla karşılaşmamış bir oyuncu artık karşılaştırılabilir profiller olmayabilir. Başlangıçtaki rastgele atama bize grupların dengeli olmasını garanti ediyordu. Filtreleme bu garantiyi bozuyor.
Bu ikilem aslında A/B testlerinin ötesinde, klinik deneylerde de karşılaşılan bir mesele. Tıpta buna intent-to-treat deniyor: hastalar tedaviye atandıkları gruba göre analiz ediliyor, tedaviyi gerçekten alıp almadıklarına bakılmıyor. Bunun sebebi bir nevi randomizasyonun sağladığı dengeyi korumak. Alternatifi, yani sadece tedaviyi fiilen alanları analiz etmek (per-protocol), meşru bir yaklaşım ama farklı bir soruyu cevaplıyor ve yukarıda bahsettiğimiz seçim yanlılığını taşıma riski var.
Biz de burada intent-to-treat yaklaşımıyla ilerleyeceğiz. Bütün oyuncular dahil, kapıya ulaşsın ulaşmasın. Bu, product kararının gerçekte nasıl verildiğiyle de uyumlu: kapıyı taşıdığında bütün oyunculara taşımış oluyorsun, sadece kapıya ulaşanlara değil. Ama şunu da aklımızda tutmakta fayda var: genel sonuçta gördüğümüz etki, kapıyı hiç görmeyen büyük bir oyuncu kitlesi tarafından seyreltilmiş olabilir. Gerçek etkinin, kapıyı deneyimleyenler arasında daha belirgin olması beklenir.
7-Gün Retention: p = 0.0016
Şimdi asıl soruya geçelim: kapının yeri retention’ı etkiliyor mu? 7 günlük retention’a bakıyoruz. gate_30 grubunda oyuncuların %19.02’si geri dönmüş, gate_40 grubunda %18.20’si. Fark 0.82 yüzde puanı, gate_30 lehine.
n_30, n_40 = len(gate_30), len(gate_40)
ret7_30 = gate_30["retention_7"].mean()
ret7_40 = gate_40["retention_7"].mean()
abs_diff = ret7_30 - ret7_40 # mutlak fark (yüzde puanı)
rel_diff = abs_diff / ret7_40 # göreli fark
print(f"gate_30 retention (7 gün): {ret7_30:.2%}")
print(f"gate_40 retention (7 gün): {ret7_40:.2%}")
print(f"Mutlak fark: {abs_diff:.2%} yüzde puanı")
print(f"Göreli fark: {rel_diff:.1%}")gate_30 retention (7 gün): 19.02%
gate_40 retention (7 gün): 18.20%
Mutlak fark: 0.82% yüzde puanı
Göreli fark: 4.5%İki oran arasındaki farkı test ettiğimizde p = 0.0016 çıkıyor.
successes = np.array([gate_30["retention_7"].sum(),
gate_40["retention_7"].sum()])
samples = np.array([n_30, n_40])
# pooled proportion altında iki oran testi
p_pool = successes.sum() / samples.sum()
se = np.sqrt(p_pool * (1 - p_pool) * (1/n_30 + 1/n_40))
z_stat = (ret7_30 - ret7_40) / se
p_value = 2 * (1 - stats.norm.cdf(abs(z_stat)))
print(f"z = {z_stat:.3f}, p = {p_value:.4f}")z = 3.164, p = 0.0016Bu oldukça ikna edici bir sayı. p = 0.002 demek, kabaca şunu söylüyor: eğer gerçekte iki grup arasında hiçbir fark olmasaydı, sırf şans eseri bu kadar ya da daha büyük bir fark gözlemleme olasılığımız binde iki civarında olurdu. Düşük bir olasılık. Geleneksel 0.05 eşiğinin çok altında. Bir sprint review’da bu sonucu göstersek, karar muhtemelen hızlı çıkar: kapıyı 30’da tut, 40’a taşıma, veri destekliyor. Ve teknik olarak bu yorum yanlış değil — veri bir fark olduğuna işaret ediyor.
Ama burada durup şunu sormamız gerekiyor: sonuç yeterince şaşırtıcı, peki ne kadar büyük?
Arada 0.82 yüzde puanlık fark var. Bunu somutlaştıralım. 100 oyuncudan gate_30’da 19’u geri dönüyor, gate_40’da 18’i. Aradaki fark — gate pozisyonunun “kurtardığı” oyuncu — 100 kişide 1’den az. Bunu tıptan ödünç aldığımız bir kavramla ifade edersek: NNT (Number Needed to Treat) = 122. Bir oyuncunun davranışını değiştirmek için bu kapı pozisyonunu 122 kişiye uygulamanız gerekiyor. Geri kalan 121 kişi için iki grup arasında pratik bir fark yok.
# NNT — Number Needed to Treat
# Bir oyuncunun davranışını değiştirmek için kaç oyuncuya
# bu kapı pozisyonunu uygulamanız gerekiyor?
nnt = 1 / abs(abs_diff)
print(f"NNT: {nnt:.0f}")
# Cohen's h — iki oran arasındaki standardize edilmiş fark
# Cohen's d ortalamalar için, h oranlar için.
h = 2 * (np.arcsin(np.sqrt(ret7_30)) - np.arcsin(np.sqrt(ret7_40)))
print(f"Cohen's h: {h:.3f}")
# Yorum ölçeği: |0.2| küçük, |0.5| orta, |0.8| büyükNNT: 122
Cohen's h: 0.021Etki Büyüklüğü: h = 0.021
Cohen’s h — iki oran arasındaki farkın standardize edilmiş hali. Burada 0.021 çıkıyor. Genel kabul görmüş sınıflandırmada: 0.2 “küçük,” 0.5 “orta,” 0.8 “büyük” etki. 0.021 bu ölçeğin neredeyse dibinde, “ihmal edilebilir” denilebilecek bir düzeyde. İki grubun retention dağılımlarını üst üste koysanız neredeyse tamamen örtüşür. Grupları karıştırıp rastgele ikiye ayırsanız, muhtemelen benzer bir “fark” gözlemlersiniz.
Peki o zaman p-value neden bu kadar küçük çıktı? Bunun cevabı örneklem büyüklüğünde — önceki yazımda futbol analitiği verisi üzerinden detaylıca ele alıyoruz. 90.000 kişilik bir veri setiyle çalışıyoruz. Bu kadar büyük bir örneklemde, çok küçük farklar bile istatistiksel olarak “şaşırtıcı” hale geliyor, çünkü şans dalgalanmalarının aralığı daralıyor. Örneklem büyüdükçe test daha hassas hale geliyor, giderek daha küçük kıpırdanmaları tespit edebiliyor. Bu kendi başına bir sorun değil. Sorun, “tespit edilebilir” ile “önemli” kelimelerinin kafamızda eşanlamlı hale gelmesiyle başlıyor.
Bu bir product kararını yönlendirmeli mi? Belki. Ama bu sorunun cevabı salt istatistikte değil, işin ekonomisine de uzanıyor: küçük bir kaymanın marjinal getirisi ve fırsat maliyeti ne olacak, başka hangi metrikler ve dinamikler etkilenecek, bu marjinal getiriyi sağlayacak analitik ve yönetsel efora değecek mi?
İstatistik sana gözlemlediğin farkın muhtemelen gerçek olduğunu söylüyor. Farkın önemli olup olmadığını söylemek onun işi değil.
# %95 güven aralığı
se_diff = np.sqrt(ret7_30 * (1 - ret7_30) / n_30
+ ret7_40 * (1 - ret7_40) / n_40)
ci_low = abs_diff - 1.96 * se_diff
ci_high = abs_diff + 1.96 * se_diff
print(f"Farkın %95 güven aralığı: [{ci_low:.2%}, {ci_high:.2%}] yüzde puanı")Farkın %95 güven aralığı: [0.31%, 1.33%] yüzde puanıGüven aralığını da hesapladık: farkın %95 güven aralığı 0.31 ile 1.33 yüzde puanı arasında çıkıyor. Farkın büyüklüğü hakkında bir perspektif sunuyor, ama dikkatli olmakta fayda var. %95 güven aralığının “gerçek fark bu aralıktadır” iddiası yok — gerçek fark bu aralığın dışında da olabilir. Güven aralığının söylediği şey aslında:
Bu yöntemi tekrar tekrar uygulasan, oluşturduğun aralıkların %95’i gerçek değeri kapsar.
Bu spesifik aralığın kapsayıp kapsamadığını bilmiyorsun. Yine de büyüklük algısı için faydalı: konuştuğumuz şey olsa olsa 1–2 yüzde puanı civarında bir etkidir.
extra_retained = abs_diff * n_40
print(extra_retained)373.06885906040173Pratik Karşılığı Ne?
gate_40 grubunda 45.489 oyuncu var. Retention oranındaki 0.82 puanlık mutlak farkı bu sayıyla çarptığımızda — yani farkın toplam havuzda kaç kişiye karşılık geldiğini hesapladığımızda — yaklaşık 373 oyuncu çıkıyor. 45.000 kişiden 373’ünün davranışı kapı pozisyonuna bağlı olarak farklılaşmış. Geri kalan yaklaşık 45.000 kişi için iki grup arasında pratik bir fark yok.
Üstelik bu farkı paraya çevirmeye çalıştığınızda işler daha da karmaşıklaşıyor. Sensor Tower’ın 2016-17 verilerine göre Cookie Cats’in indirme başına ortalama net geliri $0.63 (toplam $2M gelir, 3.2M indirme).

-
Cookie Cats gelir ve indirme verileri. Kaynak: Sensor Tower, 2016-17 dönemi.
Ama bu sayıyı doğrudan 373 ekstra tutulan oyuncuyla çarpamazsınız — çünkü $0.63 bir oyuncunun tüm yaşam döngüsünün ortalaması, ilk gün bırakanlar dahil. Bizi ilgilendiren, 7. günde hâlâ orada olan bir oyuncunun bundan sonra üreteceği marjinal ek gelir. Bu, veri setinde doğrudan hesaplayabileceğimiz bir şey değil — gelir bilgisi yok, sadece retention var. Dönemin ARPDAU benchmarklerinden kaba bir tahmin yapılabilir (Kern 2017 sunumuna göre puzzle türünde ~$0.15–$0.18), ama tahmin üstüne tahmin olur. Bir kullanıcıyı tutmanın marjinal ekonomik değerini gerçekten ölçmek, yani A/B testinden çıkan sonucu nedensel bir ekonomik etkiye çevirmek başlı başına ayrı bir alanın işi. Causal inference alanı tam olarak bu tür soruları ele alıyor; merak edenler için sevgili dostum Yiğit Aşık’ın blogu bulabileceğiniz en iyi başlangıç noktalarından.
Konuştuğumuz büyüklük algısı birkaç yüz dolar — binler basamağında dahi değiliz. Bir mühendislik sprint’inin maliyetiyle karşılaştırıldığında nerede durduğu, her şirketin kendi cevaplaması gereken bir soru.
Bu tür farkların ne kadar küçük olabileceğini, önceki yazımda futbol pressing verisi üzerinden de görmüştük — 3.646 maçla p < 0.001 çıkıyordu ama etki ihmal edilebilir düzeydeydi. Aynı dinamik burada da geçerli: büyük örneklem küçük farkları “istatistiksel olarak şaşırtıcı” kılıyor. Ama pratik olarak ne anlama geldiği, tamamen işin ekonomisine bağlı.
Şimdiye kadar madalyonun bir yüzüne baktık: significant bir sonuç aldık, ama etkinin kendisi neredeyse görünmez durumda. Şimdi öbür yüze geçelim — 1-day retention’a bakalım. Aynı 90.000 oyuncu, aynı gruplar, aynı test. Tek fark, metriğin penceresi.
ret1_30 = gate_30["retention_1"].mean()
ret1_40 = gate_40["retention_1"].mean()
abs_diff_1 = ret1_30 - ret1_40
# z-testi
p_pool_1 = (gate_30["retention_1"].sum() + gate_40["retention_1"].sum()) / (n_30 + n_40)
se_1 = np.sqrt(p_pool_1 * (1 - p_pool_1) * (1/n_30 + 1/n_40))
z_1 = abs_diff_1 / se_1
p_value_1 = 2 * (1 - stats.norm.cdf(abs(z_1)))
# güven aralığı
se_diff_1 = np.sqrt(ret1_30 * (1 - ret1_30) / n_30 + ret1_40 * (1 - ret1_40) / n_40)
ci_low_1 = abs_diff_1 - 1.96 * se_diff_1
ci_high_1 = abs_diff_1 + 1.96 * se_diff_1
print(f"gate_30 retention (1 gün): {ret1_30:.2%}")
print(f"gate_40 retention (1 gün): {ret1_40:.2%}")
print(f"Mutlak fark: {abs_diff_1:.2%} yüzde puanı")
print(f"z = {z_1:.3f}, p = {p_value_1:.4f}")
print(f"%95 güven aralığı: [{ci_low_1:.2%}, {ci_high_1:.2%}]")gate_30 retention (1 gün): 44.82%
gate_40 retention (1 gün): 44.23%
Mutlak fark: 0.59% yüzde puanı
z = 1.784, p = 0.0744
%95 güven aralığı: [-0.06%, 1.24%]1-Gün Retention: Yokluğu Kanıtlamak
gate_30’da %44.82, gate_40’da %44.23. Fark 0.59 yüzde puanı. Ve p = 0.074 — geleneksel 0.05 eşiğinin üstünde, “anlamlı değil.”
Bir PM bu sonucu görse ne der? Büyük olasılıkla: “İlk gün retention’ı gate pozisyonundan etkilenmiyor. Bir sonraki metriğe geçelim.” Dashboard’a not düşülmüş, konu kapanmış.
Ama güven aralığına bakın: -0.06’dan +1.24’e uzanıyor. Bu ne demek? Gerçek fark sıfıra çok yakın da olabilir, 1.24 yüzde puanı kadar büyük de olabilir. Veri sana “fark yok” demiyor — “bu hassasiyetle, bu örneklemle, bu sürede bir fark gösteremedim” diyor. Bu ikisi arasındaki fark, bir feature’ın kaderi kadar geniş olabilir.
İskoç hukuk sisteminde jüri üç karar verebilir: suçlu, masum, veya “kanıtlanmadı” (not proven). Çoğu hukuk sisteminde sadece ilk ikisi var — ama İskoçya üçüncü bir seçenek tanıyor: kanıtlar mahkumiyet için yeterli olmadı, ama sanığın masum olduğu da kanıtlanmadı. p > 0.05, aslında tam olarak bu karar: “kanıtlanmadı.” Ama biz onu “masum” gibi okuyoruz. Diyoruz ki, “fark yok, konu kapandı.”
Peki bunu test edebilir miyiz? “Fark yok” demek istiyorsak, farklı türde bir test lazım — fark gösteremediğimiz için değil, eşdeğerliği göstermek için tasarlanmış bir test.
Standart hipotez testlerinde başlangıç varsayımı “fark yok”. Veri seni yeterince ikna ederse “fark var” diyorsun. Ama bu testin söyleyebildiği tek şey “fark var” veya “ikna olmadım.” “Fark yok” hiçbir zaman bu testin çıktısı değil. Sessiz kalmak, onay vermek değil.
Eşdeğerlik testinde ise soruyu tersine çeviriyoruz: başlangıç varsayımı “fark var.” Veri yeterince ikna ederse “fark yok — en azından umursadığım büyüklükte bir fark yok” diyorsun. Bunun için önce “umursadığım büyüklük” sınırını kendin belirliyorsun, mesela ±1 yüzde puanı. Sonra test, gözlemlenen farkın bu sınırların içinde olduğunu gösterebilecek kadar kanıt var mı diye bakıyor.
İki farklı test, iki farklı soru. Birincisi “şüpheliyi mahkum edecek kanıt var mı,” ikincisi “şüpheliyi aklayacak kanıt var mı.” İkisine de cevap “hayır” olabilir — ve o zaman elimizde kalan şey İskoç kararı: “kanıtlanmadı.”
# TOST — Two One-Sided Tests (eşdeğerlik testi)
# Soru: "iki grup arasındaki fark ±1 yüzde puanından küçük mü?"
delta = 0.01 # ±1 yüzde puanı eşdeğerlik sınırı
# Üst sınır testi: fark < +delta mı?
z_upper = (abs_diff_1 - delta) / se_diff_1
p_upper = stats.norm.cdf(z_upper)
# Alt sınır testi: fark > -delta mı?
z_lower = (abs_diff_1 + delta) / se_diff_1
p_lower = 1 - stats.norm.cdf(z_lower)
p_tost = max(p_upper, p_lower)
print(f"Eşdeğerlik sınırları: ±{delta:.0%} yüzde puanı")
print(f"Gözlemlenen fark: {abs_diff_1:.2%}")
print(f"TOST p-değeri: {p_tost:.4f}")
print(f"Sonuç: {'Eşdeğer — fark ±1pp içinde' if p_tost < 0.05 else 'Kararsız — eşdeğerliği de kanıtlayamıyoruz'}")
# ±2pp ile tekrar deneyelim
delta_2 = 0.02
z_upper_2 = (abs_diff_1 - delta_2) / se_diff_1
p_upper_2 = stats.norm.cdf(z_upper_2)
z_lower_2 = (abs_diff_1 + delta_2) / se_diff_1
p_lower_2 = 1 - stats.norm.cdf(z_lower_2)
p_tost_2 = max(p_upper_2, p_lower_2)
print(f"\nEşdeğerlik sınırları: ±{delta_2:.0%} yüzde puanı")
print(f"TOST p-değeri: {p_tost_2:.4f}")
print(f"Sonuç: {'Eşdeğer' if p_tost_2 < 0.05 else 'Kararsız'}")Eşdeğerlik sınırları: ±1% yüzde puanı
Gözlemlenen fark: 0.59%
TOST p-değeri: 0.1080
Sonuç: Kararsız — eşdeğerliği de kanıtlayamıyoruz
Eşdeğerlik sınırları: ±2% yüzde puanı
TOST p-değeri: 0.0000
Sonuç: EşdeğerEşdeğerlik Testi: TOST
±1 yüzde puanı sınırıyla TOST kararsız. Eşdeğerliği kanıtlayamıyoruz. Ne “fark var” diyebiliyoruz, ne “fark yok.” 90.000 kullanıcıyla bile veri bize “bilmiyorum” diyor.
Bu, günlük pratikte neredeyse hiç yapılmayan bir test. Çoğu zaman akış şöyle işliyor: test çalıştır, p > 0.05 ise “etki yok” de, devam et. Ama “etki yok” demenin de bir kanıt yükü var. Fark gösterememek, fark olmadığını göstermek değil. Bu biraz, gürültülü bir kalabalıkta birinin adını seslenmek gibi — cevap gelmediyse o kişinin orada olmadığı anlamına gelmiyor. Belki orada ama sesin ulaşmadı. Daha güçlü bağırsan ya da kalabalık azalsa belki duyacaktı.
Örneklem Büyüklüğü ve Tespit Gücü
Şimdiye kadar iki farklı sonuçla karşılaştık: 7-gün retention’da p = 0.0016, “anlamlı fark var” ama etki neredeyse görünmezdi. 1-gün retention’da p = 0.074, “anlamlı fark yok” ama yokluğu da kanıtlayamıyoruz. İki sonuç da aynı 90.000 oyuncudan, aynı testten geldi. Tek değişiklik baktığımız metrikti.
Peki ya farklı olan örneklem büyüklüğü olsaydı? Aynı verideki aynı gerçekliğe, farklı büyüklükte pencerelerden baksaydık ne görürdük?
Bunu test etmemiz mümkün. Cookie Cats verisinden farklı büyüklüklerde rastgele alt örneklemler çekip her birinde aynı 7-gün retention testini çalıştıralım. Gerçeklik değişmemiş, 0.82 puanlık fark hep orada olacak. Sadece kaç oyuncuya baktığımızı değiştireceğiz.
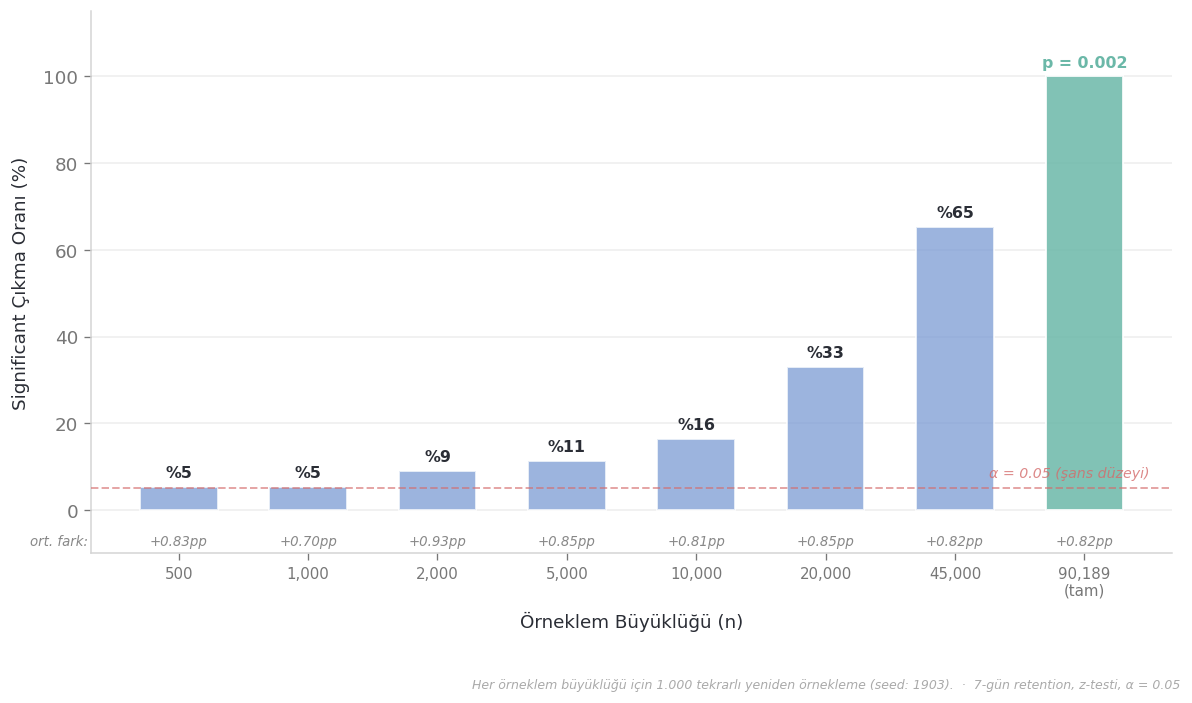
Bu grafikte bir şey dikkat çekiyor olmalı: ilk üç çubuk — 500, 1.000, 2.000 kişi — kırmızı çizginin hemen üstünde. O çizgi %5 ve şunu temsil ediyor: iki grup arasında gerçekte hiçbir fark olmasa bile, sırf örnekleme şanssızlığından dolayı testlerin %5’i significant çıkar. Yani bir test %5–6 oranında significant sonuç üretiyorsa, aslında gerçek bir sinyali şanstan ayırt edemiyor demektir. Bozuk para atmakla aynı bilgi değerinde.
Bunu şöyle düşünün: bir ürün ekibi 5.000 kullanıcıyla A/B testi çalıştırıyor. Sonuç non-significant çıkıyor. PM diyor ki “feature işe yaramadı, kill edelim.” Ama aynı feature’ı 90.000 kullanıcıyla test etseydi, p = 0.002 çıkacaktı. Feature öldürüldü — ama verinin yetersizliğinden, feature’ın etkisizliğinden değil. Ve kimse bunu bilmiyor, çünkü kimse “testimiz bu büyüklükteki bir etkiyi yakalayacak kadar güçlü müydü?” diye sormadı.
Testi Çalıştırmadan Önce Sorulması Gereken Soru
Benim fast-food analytics olarak tanımladığım kültürlerde A/B test süreci şuna benziyor: feature’ı geliştir, testi başlat, bir süre bekle, p-value’ya bak, karar ver. Ama bu süreçte kritik bir adım atlanıyor. Çünkü kimse şunu sormayı düşünmüyor: “Ne kadar küçük bir farkı umursuyorum?”
Bu soru aslında epey pratik bir soru. Diyelim ki bir mobil oyunda gate pozisyonunu değiştirmeyi düşünüyorsunuz. Engineering maliyeti belli — iki haftalık bir sprint. Peki bu sprint’in kendini amorti etmesi için retention’da minimum kaç puanlık bir artış gerekiyor? 0.5 puan mı? 2 puan mı? 5 puan mı?
Bu sorunun cevabı, testin tasarımını belirlemeli. Çünkü her test, belirli bir büyüklüğün altındaki etkilere karşı kördür ve bu körlük eşiği örneklem büyüklüğüne bağlı. Buna MDE (Minimum Detectable Effect) diyoruz: testin güvenilir şekilde yakalayabileceği en küçük fark.
Somut örnek verelim. Retention ~%18.5 olan bir oyunda:
- 2.500 kişilik gruplarla → testiniz ancak 3 yüzde puanından büyük farkları güvenilir şekilde yakalayabiliyor. 0.82 puanlık fark? Testin radarına bile girmiyor.
- 10.000 kişiye çıktığınızda → eşik 1.5 puana iniyor. Hâlâ yetmiyor.
- 45.000 kişiyle → eşik 0.73 puana düşüyor; nihayet 0.82’lik farkımız görünür hale geliyor.
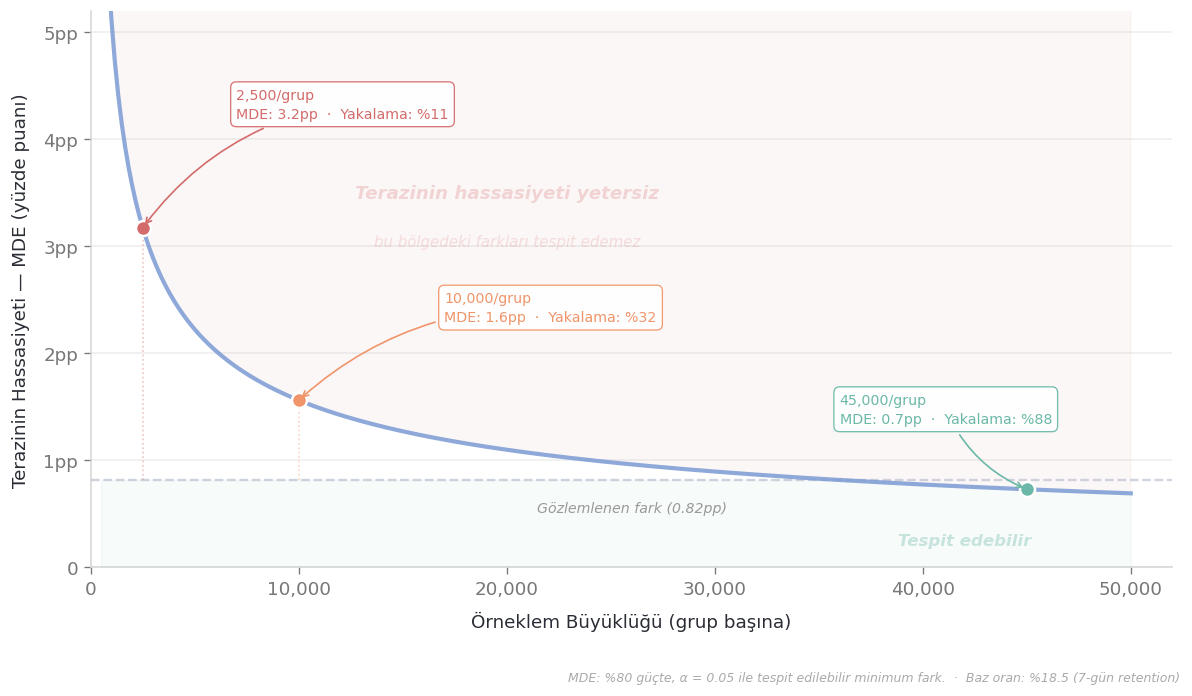
Yani, PM’seniz ve “5.000 kişiyle test ettik, significant çıkmadı, feature işe yaramıyor” dediğinizde, aslında şunu söylüyorsunuz: “3 puandan küçük farkları göremeyecek bir aletle baktım ve bir şey görmedim.” Bu, doktorun hastaya “MR’ınız temiz” demesi gibi — ama MR cihazının çözünürlüğü yalnızca 5 cm’den büyük tümörleri gösterebiliyorsa, o “temiz” kelimesi düşündüğünüz kadar rahatlatıcı değil.
Ve madalyonun diğer tarafı: iki grupta toplam 90.000 kişiyle tespit eşiğiniz 0.73 puana kadar iniyor. Bu kadar hassas bir aletle, pratikte hiçbir şey ifade etmeyen kıpırdanmalar bile “significant” çıkabiliyor. Cihaz çok hassas — ama hassasiyet, önem demek değil.
Dikkat ederseniz temel soru aşağıdakine doğru kayıyor:
- Ne kadar büyük bir farkı umursuyorum?
- Ölçüm aracım onu görecek kadar güçlü mü?
Sonuç: Bilgi Vermeyen Bir Bahis
Her A/B testini bir nevi bahis olarak düşünebiliriz. Bir hipotezimiz var, boş hipotez evrenine göre test ediyoruz — örneklemin yeterince büyük ve metriğin yeterince hassas olduğuna bahis oynuyoruz.
Non-significant bir sonuç, kaybedilmiş bir bahis değil. Bilgi vermeyen bir bahis olabilir: gürültülü kalabalıkta birinin adını seslendin, cevap gelmedi, ama belki sesin ulaşmadı. Significant bir sonuç, kazanılmış bir bahis değil. Önemsiz bir bahis olabilir: 90.000 kişiyle yüzde yarım puanlık bir kıpırdanmayı yakaladın, ama o kıpırdanma bir mühendislik sprint’ine değer mi?
Bahsin kalitesi, testi çalıştırmadan önce verilen kararlara bağlı: ne kadar küçük bir etki benim için anlamlı, bu etkiyi tespit etmek için kaç kullanıcıya ihtiyacım var, kararın her iki tarafındaki maliyetler neler. “Ne kadar küçük bir fark benim için anlamlı?” sorusunu sormamış bir ekip, testin sonucunu doğru yorumlayacak çerçeveden yoksun demektir. p-value’ya bakıp “veri konuştu” demek, soruyu sormadan cevabı okumaya çalışmak gibi.
Veri her zaman konuşuyor. Ama bazen fısıldıyor, bazen bağırıyor, bazen de omuz silkiyor. Hangisini duyduğunu bilmek, dinleme ekipmanının ne kadar hassas olduğunu bilmekle başlıyor.
Veri: Cookie Cats A/B Test (Tactile Entertainment, Rasmus Bååth aracılığıyla yayınlanmış). 90.189 oyuncu, 2016-17 dönemi. Gelir verileri: Sensor Tower. Analizler Python (NumPy, SciPy) ile yapılmıştır. Tekrarlanabilirlik için seed: 1903.